
正文
JDK自带的LinkedHashMap来实现LRU算法
【扫一扫了解最新限行尾号】
复制小程序
1 代码如下
public class LRULinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private final int maxCapacity; private static final float DEFAULT_LOAD_FACTOR = 0.75f; private final Lock lock = new ReentrantLock(); public LRULinkedHashMap(int maxCapacity) {
// true 表示让 LinkedHashMap 按照访问顺序来进行排序,最近访问的放在头部,最老访问的放在尾部
super(maxCapacity, DEFAULT_LOAD_FACTOR, true);
this.maxCapacity = maxCapacity;
} @Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
// 当 map 中的数据量大于指定的缓存个数的时候,就自动删除最老的数据。
return size() > maxCapacity;
} @Override
public boolean containsKey(Object key) {
try {
lock.lock();
return super.containsKey(key);
} finally {
lock.unlock();
}
} @Override
public V get(Object key) {
try {
lock.lock();
return super.get(key);
} finally {
lock.unlock();
}
} @Override
public V put(K key, V value) {
try {
lock.lock();
return super.put(key, value);
} finally {
lock.unlock();
}
} @Override
public int size() {
try {
lock.lock();
return super.size();
} finally {
lock.unlock();
}
} @Override
public void clear() {
try {
lock.lock();
super.clear();
} finally {
lock.unlock();
}
} public Collection<Map.Entry<K, V>> getAll() {
try {
lock.lock();
return new ArrayList<Map.Entry<K, V>>(super.entrySet());
} finally {
lock.unlock();
}
}
}
2 原理图

A 新数据插入到链表头部;
B 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
C 当链表满的时候,将链表尾部的数据丢弃。
分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
3 源码分析
put方法入口调用

super的put方法

然后调用putVal方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
因为evict为true,插入节点后都会调用afterNodeInsertion方法,当数据超出Hashmap的容量的时候,会滴啊用removeNode方法,移除head节点数据

源码中的最老的数据,当做是head,最新的数据是tail

看一下链表在get命中时候的逻辑源码处理,get方法

具体的访问方法
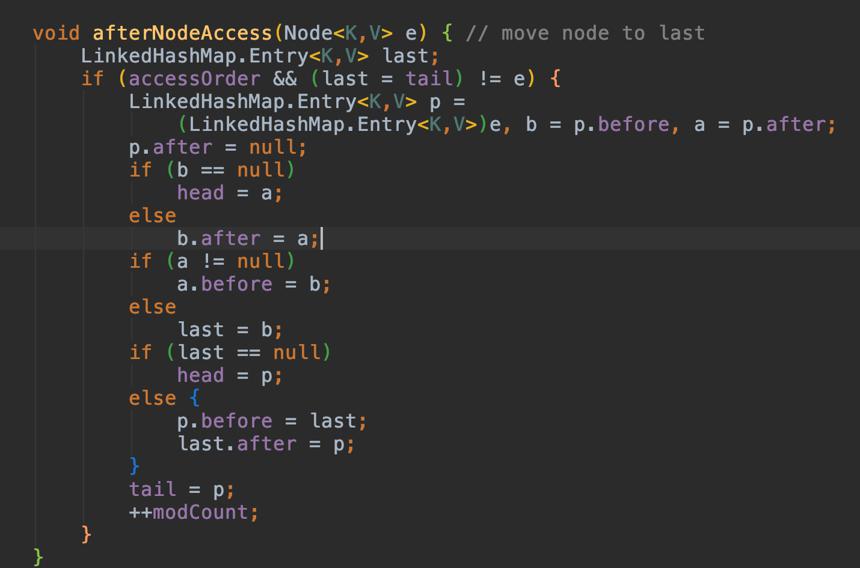
如果最后last也就是tail不是访问到的节点

linkedhashmap会自动移动当前节点到tail的位置,这就是jdk自带的linkedHashMap实现的LRU算法






