
正文
STM32 MCU一次计算优化和提速
【扫一扫了解最新限行尾号】
复制小程序
1、背景
STM32 MCU对25.6Kb数据进行压缩,丢掉每个数据的低4位然后2个字节拼接为1个字节。发现处理耗时竞达1ms以上,于是开始进行优化,最后达到200us的效果,提速5倍以上。
2、优化
2.1优化前
HAL_GPIO_WritePin(TestPB12_GPIO_Port, TestPB12_Pin, );
#if (USE_BINNING)
ImgCompressTo4Bit(img_ptr + PACKAGE_HEADER_SIZE, ImgSampBuf, IMG_SIZE);
#else
memcpy(img_ptr + PACKAGE_HEADER_SIZE, ImgSampBuf, IMG_SIZE);
#endif
HAL_GPIO_WritePin(TestPB12_GPIO_Port, TestPB12_Pin, );
该处理过程耗时1ms60us。
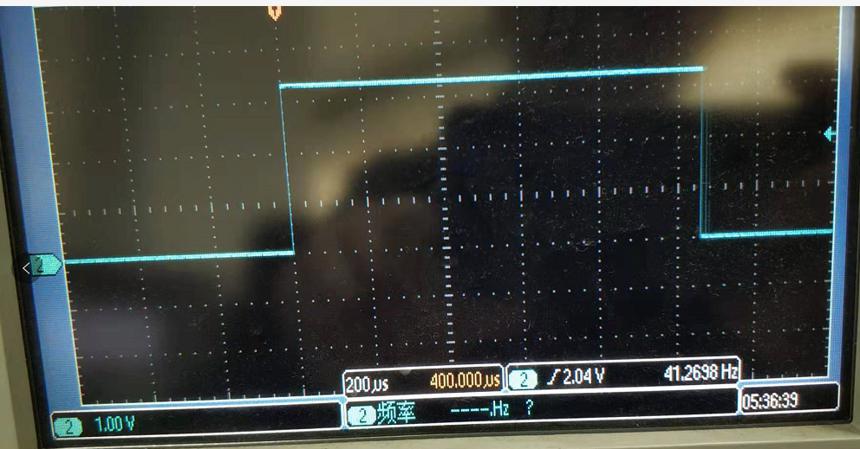
2.2 第一次优化
考虑到过多的for循环,会导致效率变低,于是一次处理4个字节。
/**
* @brief compress a arrary with high 4bit and low 4bit.
* @param[out] *pDst arrary to be filled
* @param[in] *pSrc input arrary
* @param[in] len src length
* @return dst length.
*
*/
int ImgCompressTo4Bit(uint8_t *pDst, uint8_t *pSrc, int srcLen)
{
/*loop Unrolling */
uint32_t dstLen = srcLen >> ;
uint32_t blkCnt = dstLen >> 2u; uint32_t halfOffset = dstLen;
uint8_t * ptrHigh = pSrc; // high 4 bit
uint8_t * ptrLow = pSrc + halfOffset; // low 4 bit while(blkCnt > 0u)
{
*pDst++ = ((*ptrHigh++) & 0xF0) | (((*ptrLow++) & 0xF0)>>);
*pDst++ = ((*ptrHigh++) & 0xF0) | (((*ptrLow++) & 0xF0)>>);
*pDst++ = ((*ptrHigh++) & 0xF0) | (((*ptrLow++) & 0xF0)>>);
*pDst++ = ((*ptrHigh++) & 0xF0) | (((*ptrLow++) & 0xF0)>>);
blkCnt--;
} blkCnt = dstLen % 0x4u; while(blkCnt > 0u)
{
*pDst++ = ((*ptrHigh++) & 0xF0) | (((*ptrLow++) & 0xF0)>>);
blkCnt--;
} return dstLen;
}
优化后:一次处理4个数据时间为640us。如果进一步 一次处理8个数据,时间为600us。

2.3 第二次优化
考虑到MCU是32位机器,那么使用u32类型数据进行处理,可以提高效率。
int ImgCompressTo4Bit(uint8_t *pDst, uint8_t *pSrc, int srcLen)
{
/*loop Unrolling */
uint32_t dstLen = srcLen >> ;
uint32_t blkCnt = dstLen >> 2u; uint32_t halfOffset = dstLen;
uint32_t * ptrHigh = (uint32_t*)pSrc; // high 4 bit
uint32_t * ptrLow = (uint32_t*)(pSrc + halfOffset); // low 4 bit
uint32_t * dst = (uint32_t*)pDst; while(blkCnt > 0u)
{
*dst++ = ((*ptrHigh++) & 0xF0F0F0F0) | (((*ptrLow++) & 0xF0F0F0F0)>>);
blkCnt--;
} blkCnt = dstLen % (0x4u); while(blkCnt > 0u)
{
*dst++ = ((*ptrHigh++) & 0xF0F0F0F0) | (((*ptrLow++) & 0xF0F0F0F0)>>);
blkCnt--;
} return dstLen;
}
优化后速度达到240us。

2.4 第三次优化
同样考虑降低for循环的次数,一次处理4个u32,实际上是16个字节的数据。
int ImgCompressTo4Bit(uint8_t *pDst, uint8_t *pSrc, int srcLen)
{
/*loop Unrolling */
uint32_t dstLen = srcLen >> ;
uint32_t blkCnt = dstLen >> 2u >> 2u; uint32_t halfOffset = dstLen;
uint32_t * ptrHigh = (uint32_t*)pSrc; // high 4 bit
uint32_t * ptrLow = (uint32_t*)(pSrc + halfOffset); // low 4 bit
uint32_t * dst = (uint32_t*)pDst; while(blkCnt > 0u)
{
*dst++ = ((*ptrHigh++) & 0xF0F0F0F0) | (((*ptrLow++) & 0xF0F0F0F0)>>);
*dst++ = ((*ptrHigh++) & 0xF0F0F0F0) | (((*ptrLow++) & 0xF0F0F0F0)>>);
*dst++ = ((*ptrHigh++) & 0xF0F0F0F0) | (((*ptrLow++) & 0xF0F0F0F0)>>);
*dst++ = ((*ptrHigh++) & 0xF0F0F0F0) | (((*ptrLow++) & 0xF0F0F0F0)>>);
blkCnt--;
} blkCnt = dstLen % (0x4u*0x4u); while(blkCnt > 0u)
{
*dst++ = ((*ptrHigh++) & 0xF0F0F0F0) | (((*ptrLow++) & 0xF0F0F0F0)>>);
blkCnt--;
} return dstLen;
}
优化后速度达到180--200us左右。

3、总结
基于c语法的优化:减少循环处理的次数。
基于芯片特性的优化:使用u32数据,提高处理效率。
经过3次简单的优化,1ms60us的处理降低到200us实现原有的操作。





